Why this matters: AI is no longer confined to just reading text. By understanding multiple sensory inputs, AI systems are becoming exponentially more powerful and aligned with human perception.
Attention Experiment: The Blindfolded AI
Imagine you are trying to figure out if a storm is coming. Do you only read the weather report? No. You look at the sky, you hear the thunder, and you feel the drop in temperature.
Sensory Deprivation Hook
Click the buttons below to "sense" a hidden object as an AI would. Notice how each piece of information builds a clearer picture.
For a long time, Artificial Intelligence was forced to experience the world like someone trapped in a dark room with only a typewriter. Today, AI has opened its eyes and ears. This is the dawn of Multimodal AI.
Welcome to the Multimodal Era
A modality is simply a type of data or a mode of communication. Text is a modality. Images are a modality. Audio is a modality.

Unimodal AI processes only one type of data. Early chatbots could only read and generate text. An image classifier could only look at photos but couldn't read a paragraph about the photo.
Multimodal AI processes and connects multiple types of data simultaneously. It can look at a photo of your fridge, read your dietary preferences in a text prompt, and generate a spoken audio recipe.
By breaking out of the "text-only" silo, AI can suddenly tackle complex reasoning tasks that require context from different domains, much like a human brain.
Let's Check Your Understanding
Under the Hood: How Modalities Combine
How does a computer know that the word "Dog", the sound of a "Bark", and a picture of a "Golden Retriever" are all related? The secret lies in Joint Embedding Spaces.
AI converts all data into lists of numbers (vectors). In a multimodal system, the model is trained so that the image vector of a dog and the text vector of the word "dog" land right next to each other in a mathematical "space".
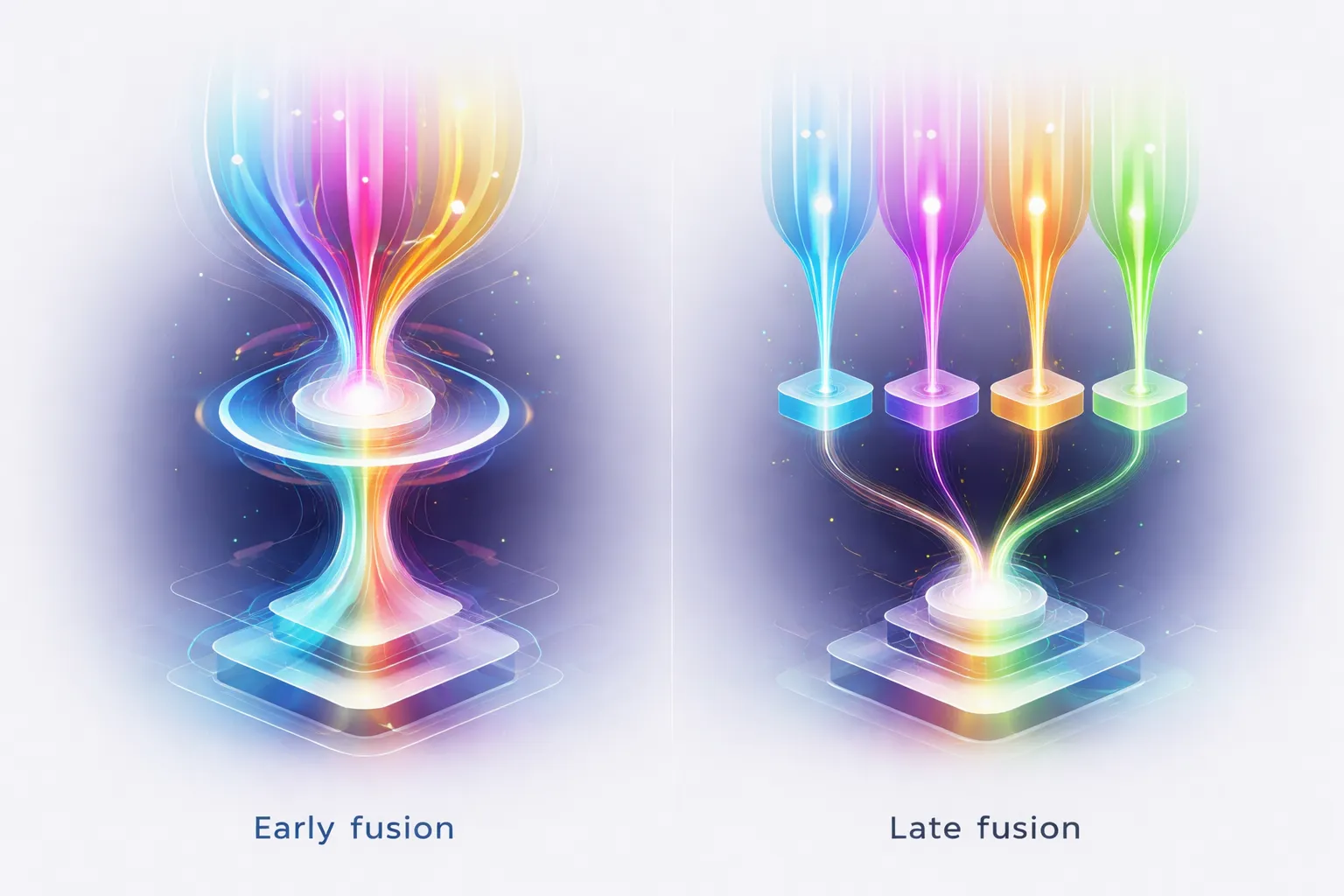
The Art of Fusion
Engineers have to decide when to combine these different senses. Click the cards to flip them and learn the two main strategies:
Early Fusion
(Click to flip)
Late Fusion
(Click to flip)
Technical Architectures: Transformers & Cross-Attention
Modern Multimodal AI relies heavily on Transformer architectures. Originally designed for text, Transformers have been adapted to process images (Vision Transformers) and audio.
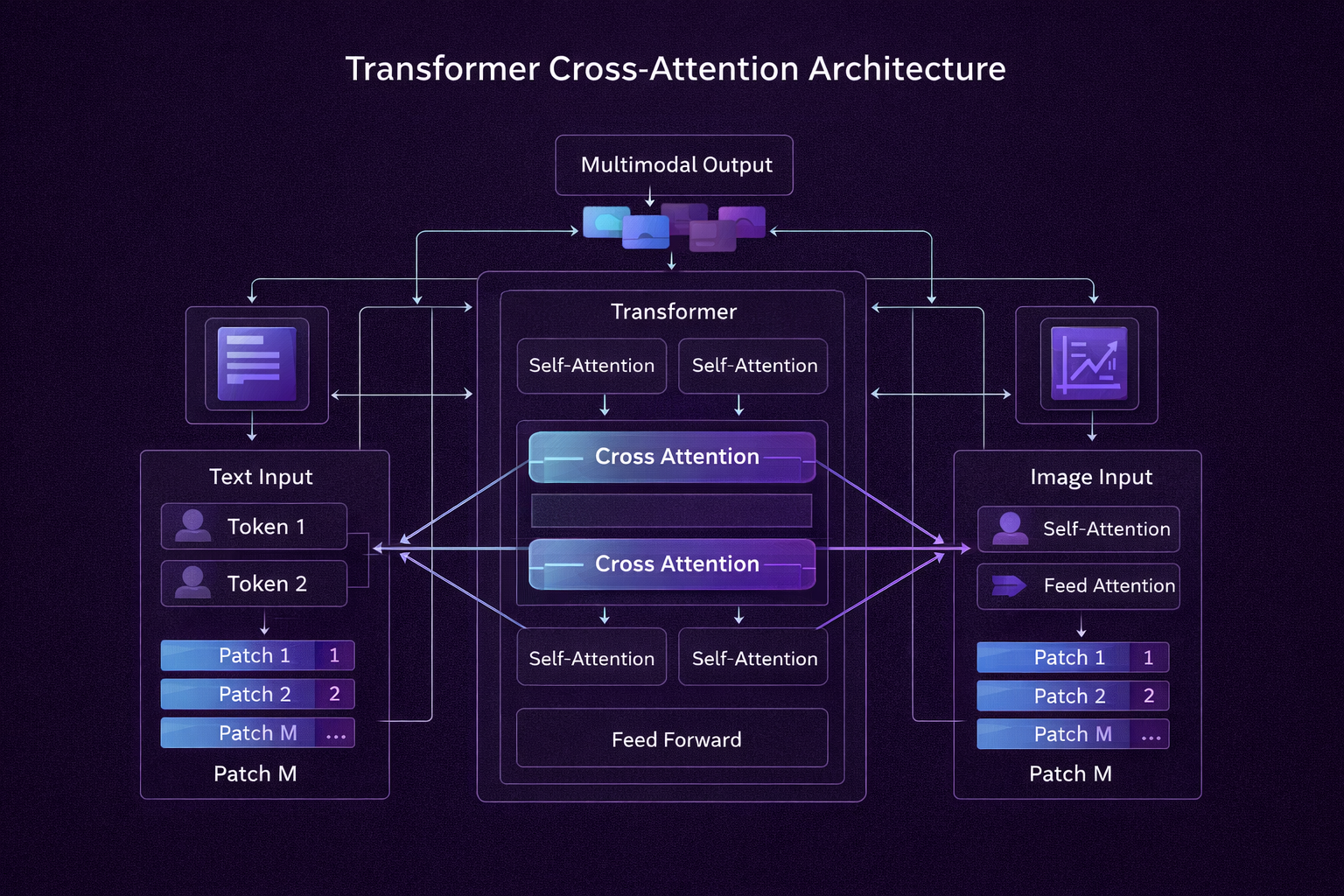
How Modalities Talk to Each Other
The secret sauce is Cross-Attention. Imagine an AI looking at a photo of a busy street while reading the text "red car."
- Self-Attention: The model looks at parts of the image to understand the visual context (the road, the buildings).
- Cross-Attention: The model maps the word "red car" directly to the specific pixels representing the red car in the image.
By using separate Encoders for each modality and projecting them into a shared latent space, the system builds a cohesive understanding before passing the data to a Decoder.
Interactive: The Distance of Meaning
In a Joint Embedding Space, concepts that are similar are placed close together mathematically, even if they come from different modalities (like text vs. image).
Joint Embedding Space Simulator
In a joint embedding space, a text prompt and an image are converted into numerical vectors. The closer they are, the higher the Cosine Similarity.
When you evaluate the distance between vectors, you are doing exactly what Cross-Attention does: computing how similar the text and the image are to match or generate appropriate outputs.
Instruct Tuning & Alignment
Just because an AI can process text and images doesn't mean it acts like a helpful assistant. It requires Instruct Tuning—training on thousands of examples of human interactions to learn how to respond.
The Alignment Game
Imagine a user uploads a photo of a broken bicycle chain and asks: "What is this?"
Which response is more aligned with a helpful AI assistant?
By using RLHF (Reinforcement Learning from Human Feedback), developers teach multimodal systems to not just identify data, but to interact with humans safely and effectively.
Superpowers in the Real World
Multimodal AI isn't just a lab experiment. It is actively reshaping industries by providing holistic understanding.

- Autonomous Vehicles: Fusing camera feeds (Vision), LIDAR (3D spatial), and GPS (Text/Coordinate) to safely navigate complex environments in real-time.
- Healthcare: Analyzing an MRI scan (Vision) while simultaneously referencing a patient's historical medical records (Text) to suggest a diagnosis.
- Accessibility: Apps that allow visually impaired users to point their phone camera at an object and hear a rich audio description of what is in front of them.
Let's Check Your Understanding
The Hurdles We Still Face
Building a system that can see, hear, and read all at once is incredibly difficult. Here are the main challenges AI researchers are actively trying to solve:

It's hard to perfectly sync different data streams. If a video is out of sync with its audio by even half a second, the AI learns the wrong associations.
Processing high-resolution video and text simultaneously requires massive server farms and expensive GPUs.
Sometimes the AI relies too heavily on the easiest modality. For example, in a video understanding task, it might just read the subtitles and completely ignore what is visually happening on screen.
Key Takeaways
- Multimodal AI processes and connects multiple data types (text, images, audio, video) simultaneously.
- Unlike Unimodal AI, it can reason across domains, enabling human-like perception.
- It uses Joint Embedding Spaces to mathematically relate different modalities (e.g., mapping the image of an apple to the text "apple").
- Fusion strategies include Early Fusion (combining raw data) and Late Fusion (combining individual processing results).
- Modern systems use Transformer architectures and Cross-Attention to map elements from different modalities (like matching the word "red car" to red pixels).
- Major challenges include computational cost, data alignment, and preventing one modality from dominating the others.
Next, you will take a short assessment to verify your understanding. A score of 80% or higher is required to earn your certificate.
Assessment Starting
You are about to begin the assessment. Select the best answer for each question.